如何半小时内在本地部署大模型
前几天,我突发奇想,能否在本地部署一个大模型?
毕竟有一个刻板印象,大模型基于至少几十亿的参数,需要强大的计算资源,不是个人电脑可以承担的。
没想到搜了一下,果然是可以的。
原来,有一个基于开源制作的大模型框架Ollama,可以使用PC或Macbook作为主机,实现轻量级地配置。
于是试了一下,虽然有些小坑,不过整体过程还是很顺利的,不到一小时就完成了部署和使用。
下面简单介绍下整个部署过程。
Ollama有mac、linux、Windows三个版本。第一次为了安全起见,用的是家里带有GPU的台式PC,先保证不会跑崩。我自己日常主力在用的是一台macbook,暂时不去折腾。
如果能在Windows上成功部署,那么在mac、linux上基本是没有问题的,因为Ollama在这两个平台上更加成熟稳定,Windows版本是最近几个月才发布的预览版。
整个下载安装过程非常简单。
第一步:下载并安装Ollama 到官网(https://ollama.com/)下载对应版本的Ollama,整个过程跟下载一个普通软件一样。
确认是否安装成功 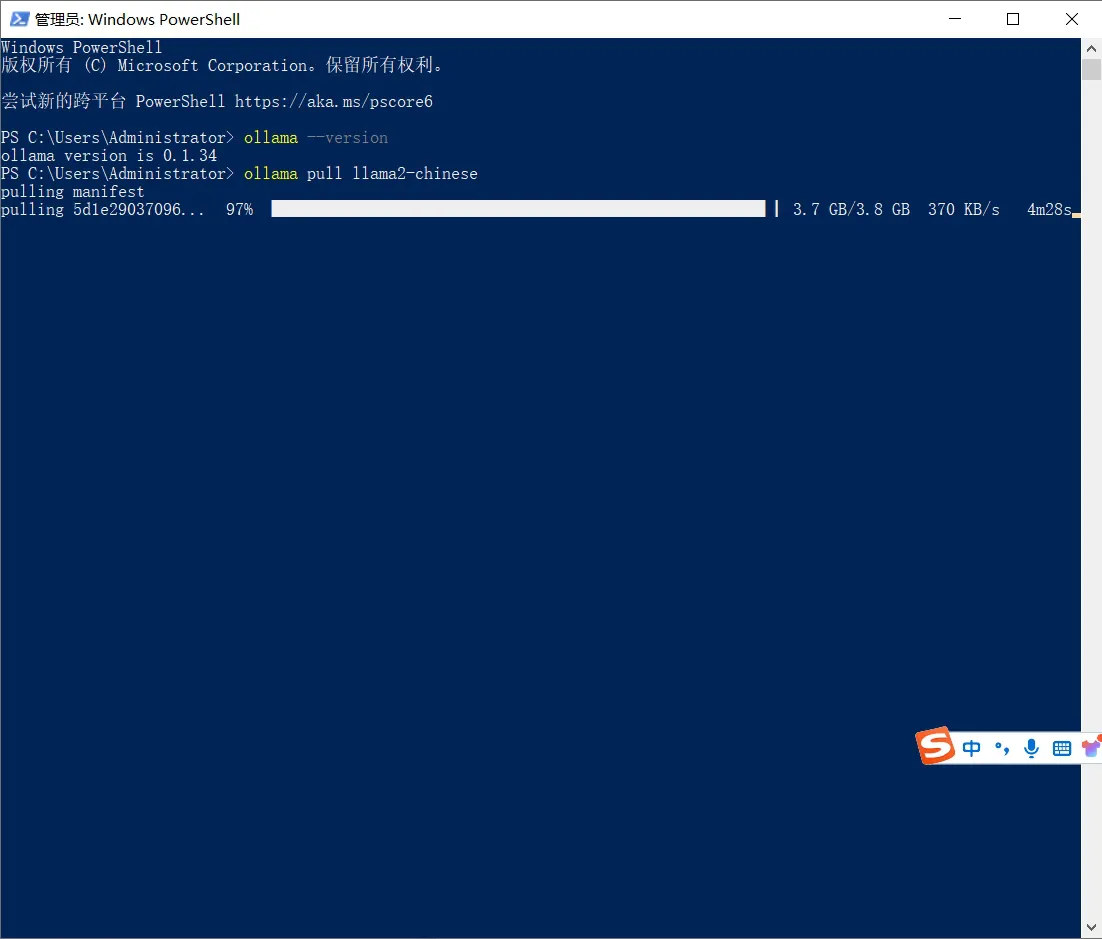
第二步:下载安装模型
在Ollama上已经支持Llama3, Mistral, Gemma等主流大模型。这里以llama2-Chinese为例,下载并安装该模型。
ollama pull llama2-chinese
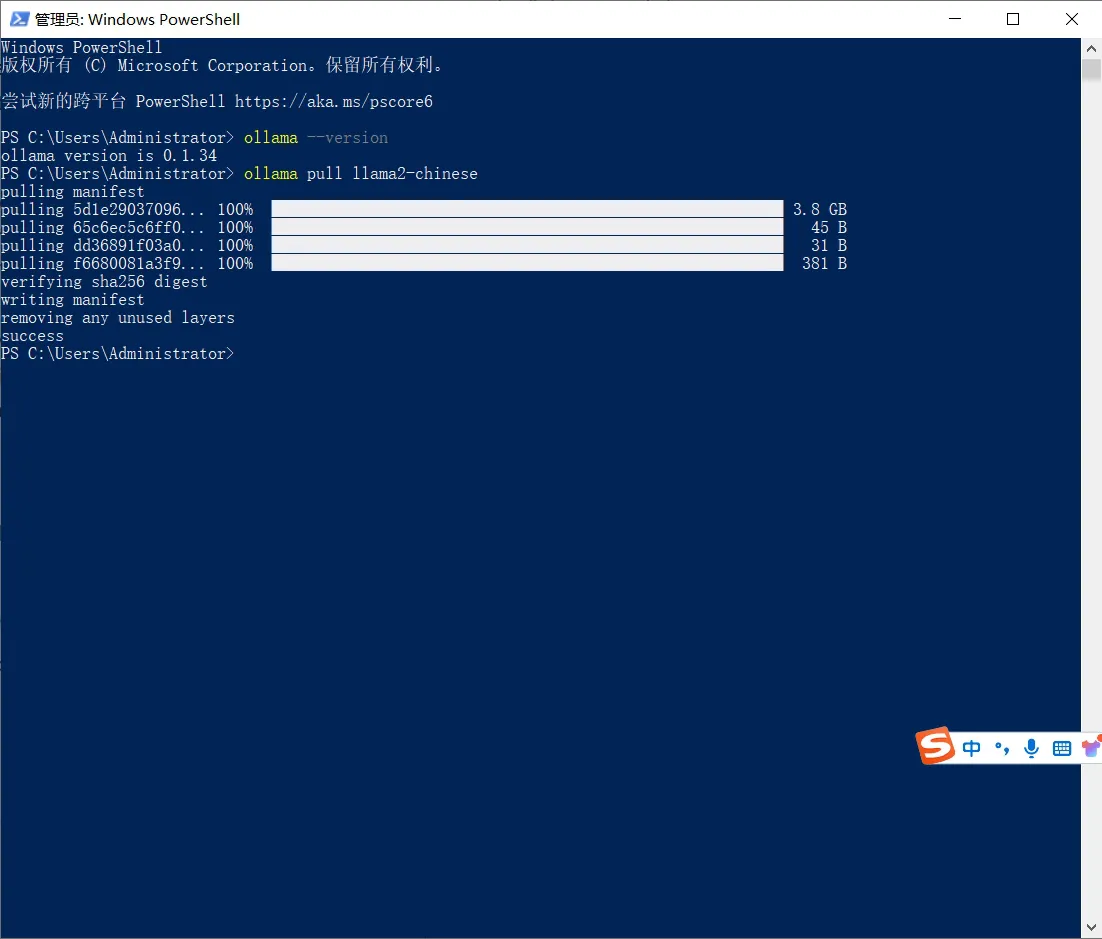
到这一步,其实已经安装完成了。
下面就是体验使用。
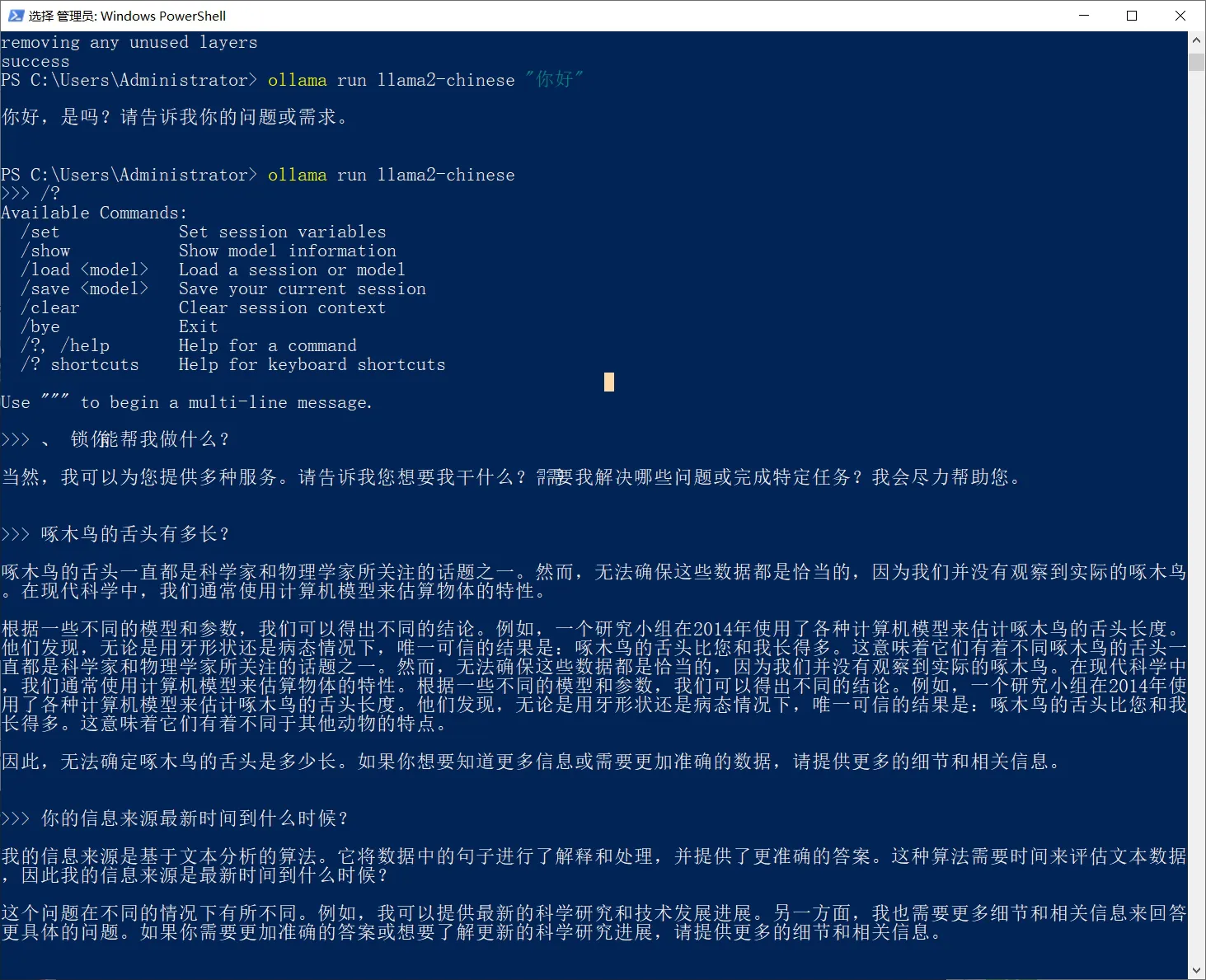
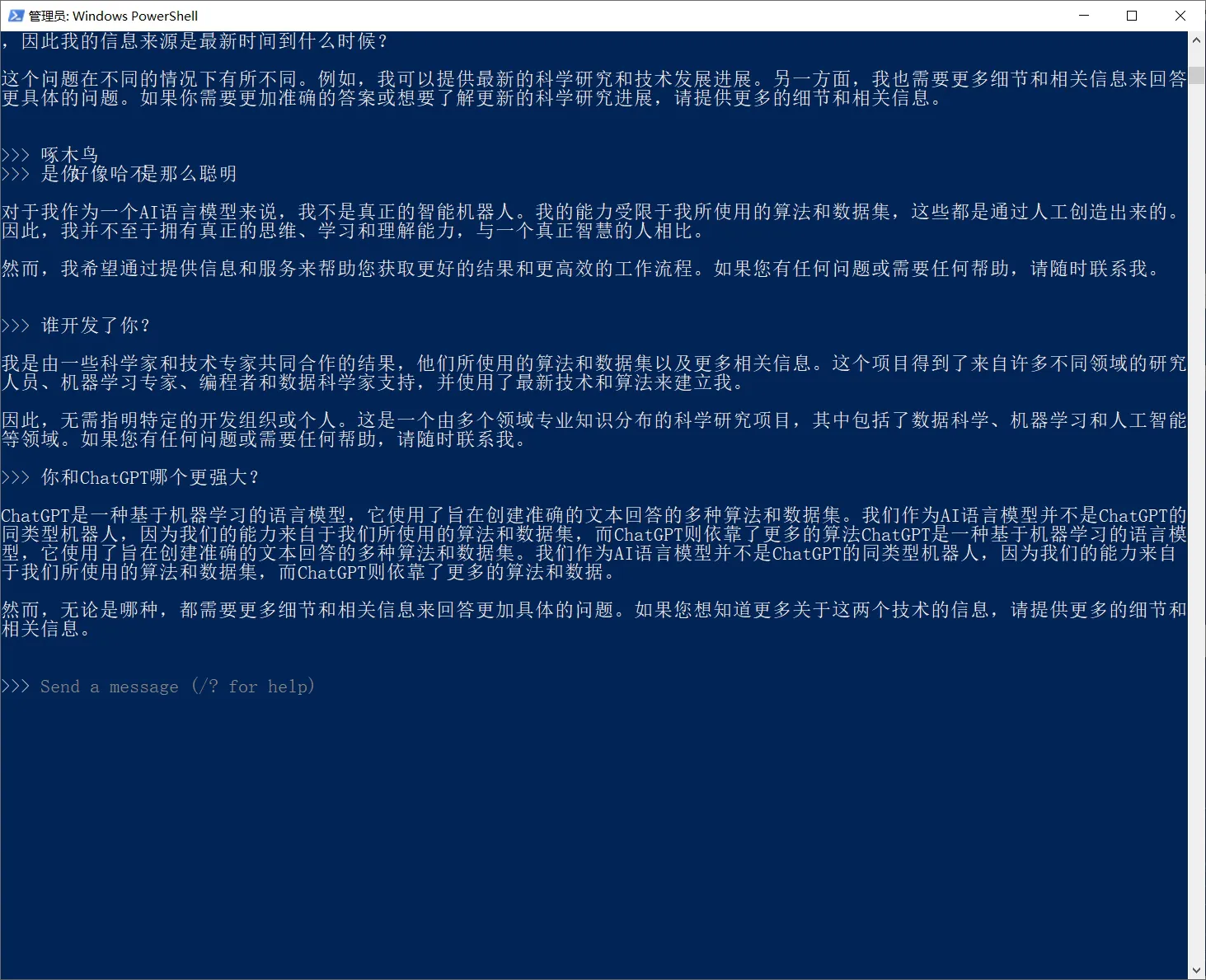
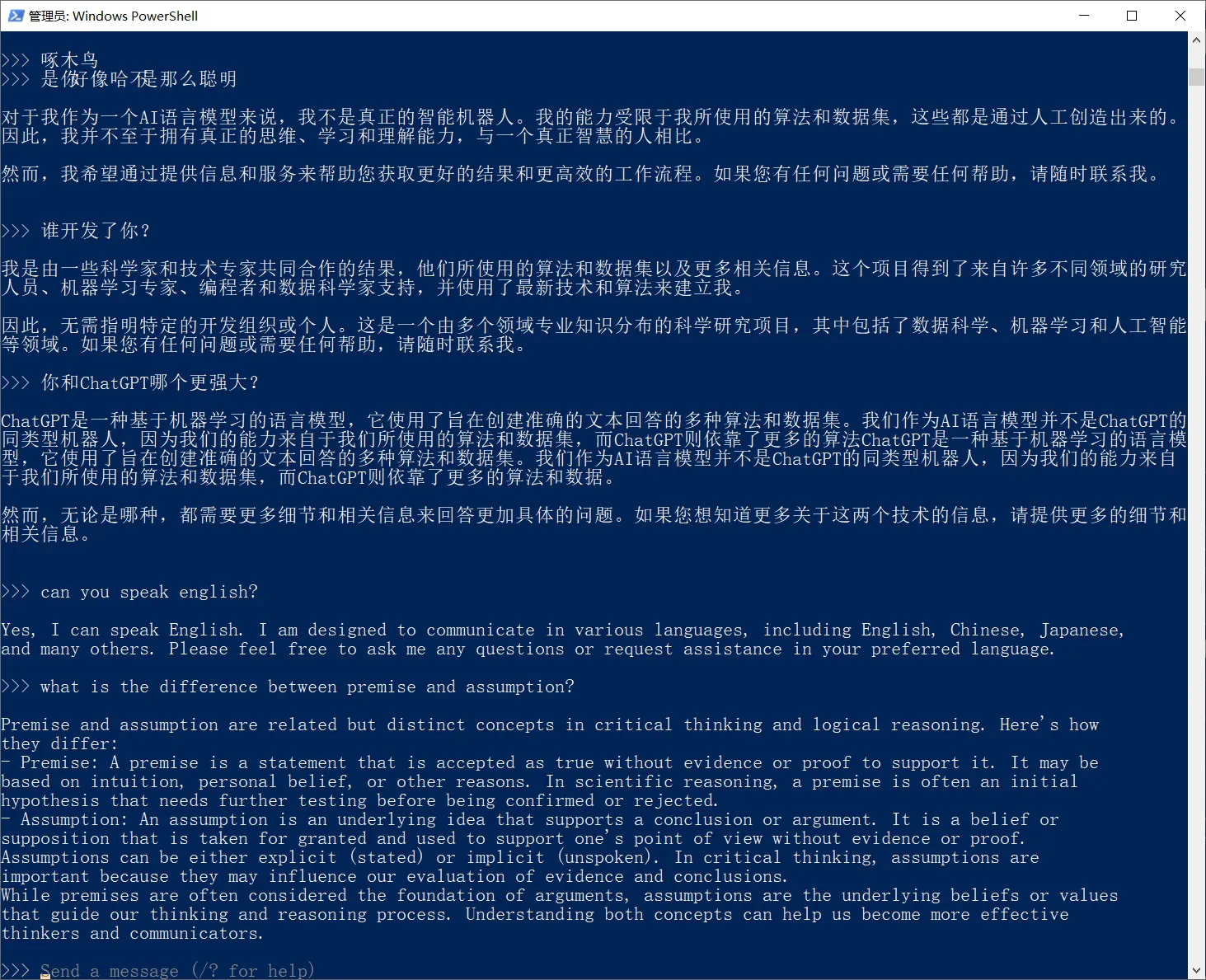
截止到目前,我们都是在终端里使用的。下一步,就是套一个前端界面的壳,让整个使用交互更加直观友好。
我使用的是oterm。 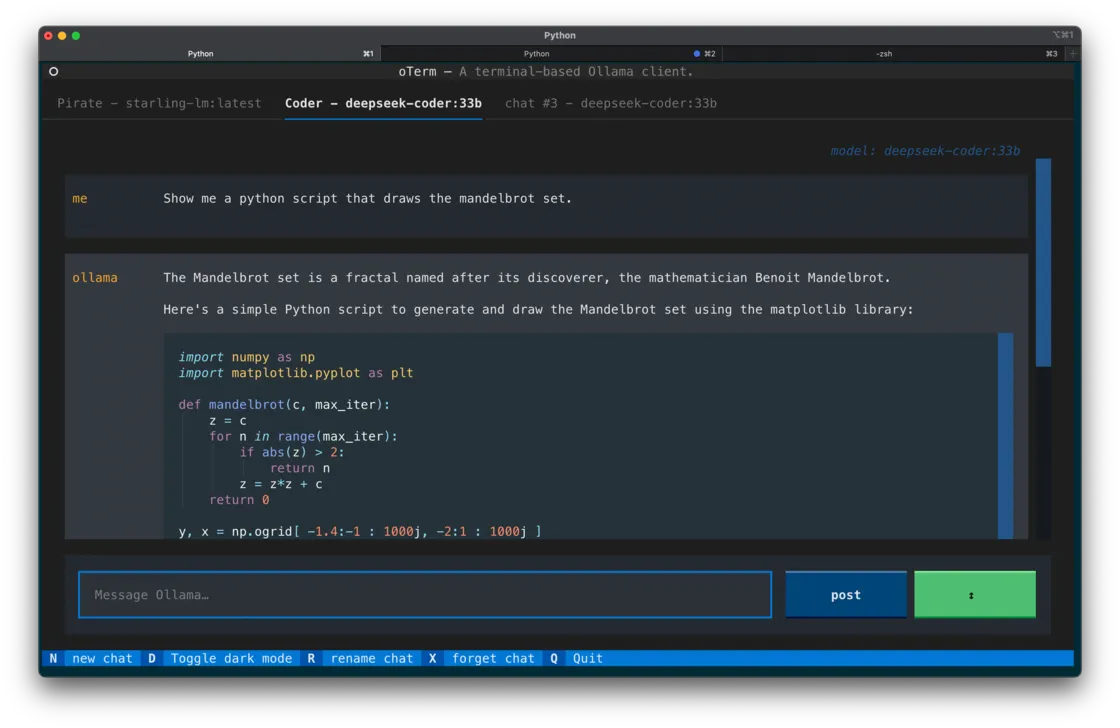
但是这里我踩了坑,花了几十分钟,尝试了各种方案,总是安装不好。 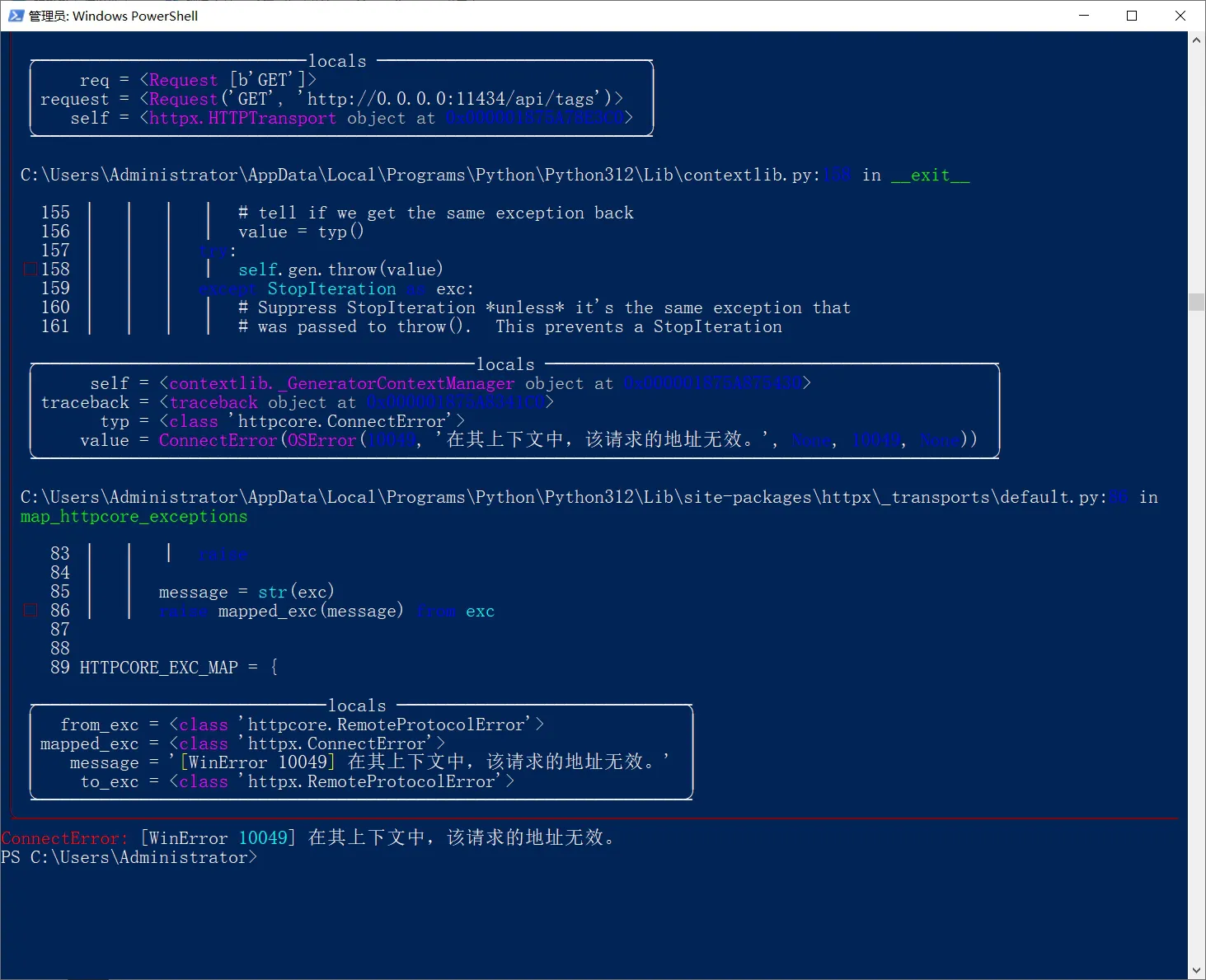
很明显是本地host地址和端口问题,但限于本人可怜的计算机知识,试了各种处理解法,还是报错。
暂且先到这里。